Automazione n8n LinkedIn
L'evoluzione del content marketing con n8n
Oggi, la velocità con cui le informazioni tecniche diventano obsolete è impressionante. Per un professionista IT o un'azienda tech, mantenere una presenza costante su LinkedIn non è più solo una questione di "branding", ma di autorità. Tuttavia, scrivere contenuti di qualità, verificare le fonti e generare immagini accattivanti richiede ore. Qui entra in gioco l'automazione n8n LinkedIn.
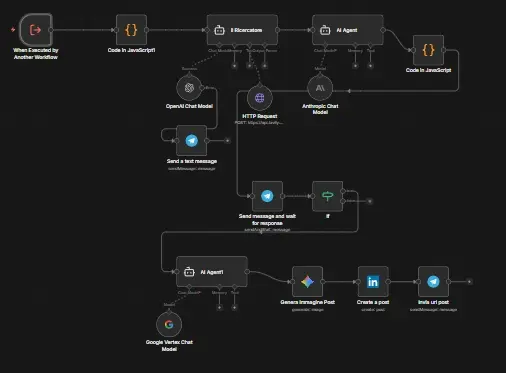
Utilizzare n8n come orchestratore permette di collegare strumenti disparati (Telegram per l'input, Tavily per la ricerca, OpenAI e Anthropic per la logica, e LinkedIn per l'output) in un unico flusso coerente. Non stiamo parlando di semplice "spam" automatizzato, ma di un sistema Human-in-the-loop dove l'intelligenza artificiale potenzia la ricerca e la stesura, mentre l'umano mantiene il controllo editoriale finale. In questa guida, analizzeremo il workflow che permette di inviare un semplice topic su Telegram e vederlo trasformato in un post professionale pronto per la pubblicazione.
Architettura del workflow: dal trigger alla pubblicazione
Il workflow fornito è un capolavoro di ingegneria low-code. Non si limita a passare testo da un punto A a un punto B, ma implementa una vera e propria pipeline di validazione dei dati. La struttura si divide in tre macro-aree:
-
Ingestion & Research: Ricezione dell'input e verifica dei fatti tramite agenti autonomi.
-
Creation & Review: Generazione del testo, dell'immagine e attesa dell'approvazione umana.
-
Deployment: Pubblicazione su LinkedIn e feedback all'utente.
Questa architettura risolve uno dei problemi principali dell'IA generativa: le allucinazioni. Grazie all'uso dell'agente "Il Ricercatore" con accesso a Tavily Search, il contenuto non è basato solo sulla conoscenza statica del modello, ma su dati freschi di giornata.
Fase 1: Input e pulizia dei dati con JavaScript
Il flusso inizia quando un altro workflow o un trigger esterno invia un messaggio (il "topic"). Il primo nodo critico è un blocco di codice JavaScript che esegue il "sanitizing" della stringa.
// Esempio di pulizia input nel nodo 'Code in JavaScript1'
// Questo snippet rimuove tag specifici per evitare che sporchino la ricerca
$input.first().json.message = $input.first().json.message.replace('#linkedinpost','');
return $input.all();
Questo passaggio è fondamentale perché spesso gli utenti utilizzano hashtag di comando su Telegram per istruire il bot. Rimuoverli prima di inviare il testo all'agente di ricerca previene errori di interpretazione nelle query di Google o Bing.
Fase 2: L'agente di ricerca con Tavily e GPT-4o
Il cuore pulsante della verifica è il nodo "Il Ricercatore". Si tratta di un Agent di LangChain che utilizza GPT-4o come cervello e un tool di HTTP Request configurato per interrogare le API di Tavily.
Il system prompt è estremamente rigido: impone all'IA di riportare solo fatti verificabili e di etichettare esplicitamente le informazioni mancanti con la dicitura "NON SPECIFICATO NELLE FONTI". Questo approccio trasforma l'automazione in un assistente giornalistico rigoroso.
Dato Tecnico: L'integrazione di Tavily con
search_depth: "advanced"permette di scansionare fino a 10 fonti simultaneamente, estraendo solo il contenuto testuale rilevante e riducendo il rumore tipico delle pagine web (header, footer, pubblicità).
Fase 3: Copywriting multi-modale con Claude Haiku
Una volta ottenuti i dati grezzi e verificati, il testimone passa ad un altro agente AI, questa volta basato su Claude Haiku 4.5 (o versioni correnti nel 2026). Perché cambiare modello?
-
GPT-4o è eccellente nel ragionamento logico e nella sintesi di dati complessi.
-
Claude è universalmente riconosciuto per uno stile di scrittura più naturale, meno "robotico" e più propenso a seguire linee guida stilistiche strette (come il limite di 2000 caratteri e l'uso di emoji funzionali).
L'agente di copywriting riceve l'output strutturato del ricercatore e lo trasforma in un post LinkedIn seguendo un template che include: Hook, contesto tecnico, 3-5 punti chiave e una CTA (Call to Action) neutra.
Fase 4: Human-in-the-loop e approvazione via Telegram
L'automazione totale è rischiosa. Il workflow include quindi un nodo Telegram: Send message and wait for response. L'utente riceve il testo generato sul proprio smartphone e deve cliccare su "Si" o "NO" tramite una tastiera inline.
Se l'utente approva, il flusso prosegue verso la generazione dell'immagine. Se rifiuta, il processo si arresta, evitando la pubblicazione di contenuti non idonei. Questo pattern è noto come Human-Augmented Automation.
Fase 5: Prompt Engineering e generazione immagini con Gemini
Dopo l'approvazione, il workflow attiva la sezione visuale. Non viene generata un'immagine a caso; un agente dedicato ("AI Agent1") agisce come Prompt Engineer. Legge il testo del post e crea una descrizione visiva ottimizzata per modelli come Flux o Google Gemini Nano Banana Pro.
// Logica concettuale del nodo di parsing post-AI
const tag = '# POST LINKEDIN';
const fullText = $input.first().json.output || "";
let finalPost = fullText;
if (fullText.includes(tag)) {
finalPost = fullText.split(tag)[1].trim();
}
return [{ json: { post_text: finalPost } }];
Il prompt generato evita testi e interfacce (spesso renderizzati male dall'IA) preferendo metafore visive (es. "glowing folders in a futuristic pipeline"). L'immagine finale viene poi inviata al nodo LinkedIn insieme al testo per la pubblicazione definitiva.
Tabella comparativa: Modelli AI nel workflow
| Nodo | Modello AI | Ruolo Principale | Punto di Forza |
| Il Ricercatore | GPT-4o | Fact-checking | Logica e precisione estrattiva |
| AI Agent (Copy) | Claude Haiku | Scrittura Post | Stile naturale e concisione |
| AI Agent1 (Prompt) | Gemini 2.5 Flash | Visual Design | Comprensione semantica per immagini |
| Generatore Immagine | Gemini Nano Banana Pro | Rendering | Alta fedeltà visiva |
FAQ
Perché usare n8n invece di Zapier per LinkedIn?
n8n offre un controllo granulare sugli agenti AI (LangChain) e permette di gestire flussi complessi con attese (Wait nodes) senza costi esorbitanti per ogni step. La possibilità di ospitare n8n sul proprio server garantisce inoltre una maggiore privacy dei dati aziendali.
Come posso gestire gli errori se l'API di OpenAI fallisce?
Nel workflow è presente un'impostazione onError: "continueErrorOutput" e un nodo Telegram di notifica errore ("OpenAi ha fallito"). Questo assicura che lo sviluppatore sia avvisato immediatamente se una chiave API scade o se il servizio è down.
Posso pubblicare su una Pagina Aziendale invece che sul profilo personale?
Sì, è sufficiente configurare le credenziali dell'app LinkedIn con i permessi w_organization_social invece di w_member_social. Il nodo LinkedIn di n8n supporta entrambi i tipi di destinazione.
Conclusione e Next Steps
Questo workflow rappresenta lo stato dell'arte dell'automazione n8n LinkedIn. Non è solo un risparmio di tempo, ma un moltiplicatore di qualità che permette di trasformare un'idea veloce su Telegram in una presenza professionale e autorevole sul social network più importante per il business.
L'integrazione di modelli diversi (GPT, Claude, Gemini) dimostra come l'approccio "model-agnostic" sia la scelta vincente per ottenere il meglio da ogni tecnologia disponibile.
Hai bisogno di implementare un'automazione n8n avanzata per la tua azienda a Milano o da remoto? CONTATTAMI per una consulenza su misura e trasforma i tuoi processi manuali in flussi di lavoro intelligenti.
Ti piacerebbe che aggiungessi una guida su come configurare le API di LinkedIn per questo specifico workflow?
